New Tools in the World of Graphs
I’m exploring the use of two new tools in my work. One with immediate payoff, and one more long term. The first tool is logseq. Loqseq is one of a number (Roam, Obsidian, Dendron) of graph based note-taking tools available online. Notes in these tools are saved as markdown (plain text) files and rendered in the applications. Taking notes in logseq for work has paid off in several ways.
First, these tools are a great way to build a wiki site of your accumulated knowledge as a substitute building html web pages. One just needs to learn the basics of markdown (which is not hard) to easily link between different pages of your notes. Images can be inserted, via the regular markdown format1. In addition to the links that the user explicitly creates, logseq also creates links between pages whenever a word is used in one page that is the title of another page. This is extremely useful when trying to see anywhere within your notes (some of which could have been taken by different people) that a certain subject has been documented. Logseq also allows you to mark todo items within the notes. These todo items can be gathered in one location by using queries within the pages to gather all todos matching arbitrary criteria across many pages on to one page. My favorite feature is logseq’s dated journal file that goes along with your notes. A page is created for each day. I’ve used these files to take all of my meeting notes. The notes are stored on the day they are taken, but logseq automatically creates a link to these notes in any page where the words in the meeting notes match the title of a page.
The knowledge graph of all of one’s pages is displayed graphically in logseq. This is a cool feature of the tool. I find it fun to look at, though I have not yet found any real practical use of it. The image at the top of this post is the knowledge graph for my personal learning that I store at home, the one for my work notes looks very similar.
Logseq allows the markdown text files to be stored locally. If your work involves information that you can’t put on the cloud, logseq is a good solution. I am sharing logseq files with two people now and it works OK. This to me is the most important remaining test of whether this tool can be really impactful. It has to be able to allow a whole team to add information to it without people stepping on each other.
Logseq is a tool that I picked up quickly and has an immediate impact. The other tool related to graphs that I am experimenting with is a graph-based-database, specifically the property-graph-database Neo4j. My interest in a graph-database started because I have built a traditional relational database with sqlite as the backbone of an application to track progress on the definition and manufacture of new hardware on a development program. The relational database does the job, but I have run into a few challenges that made me interested in what the different no-sql databases, including graph-based databases could offer.
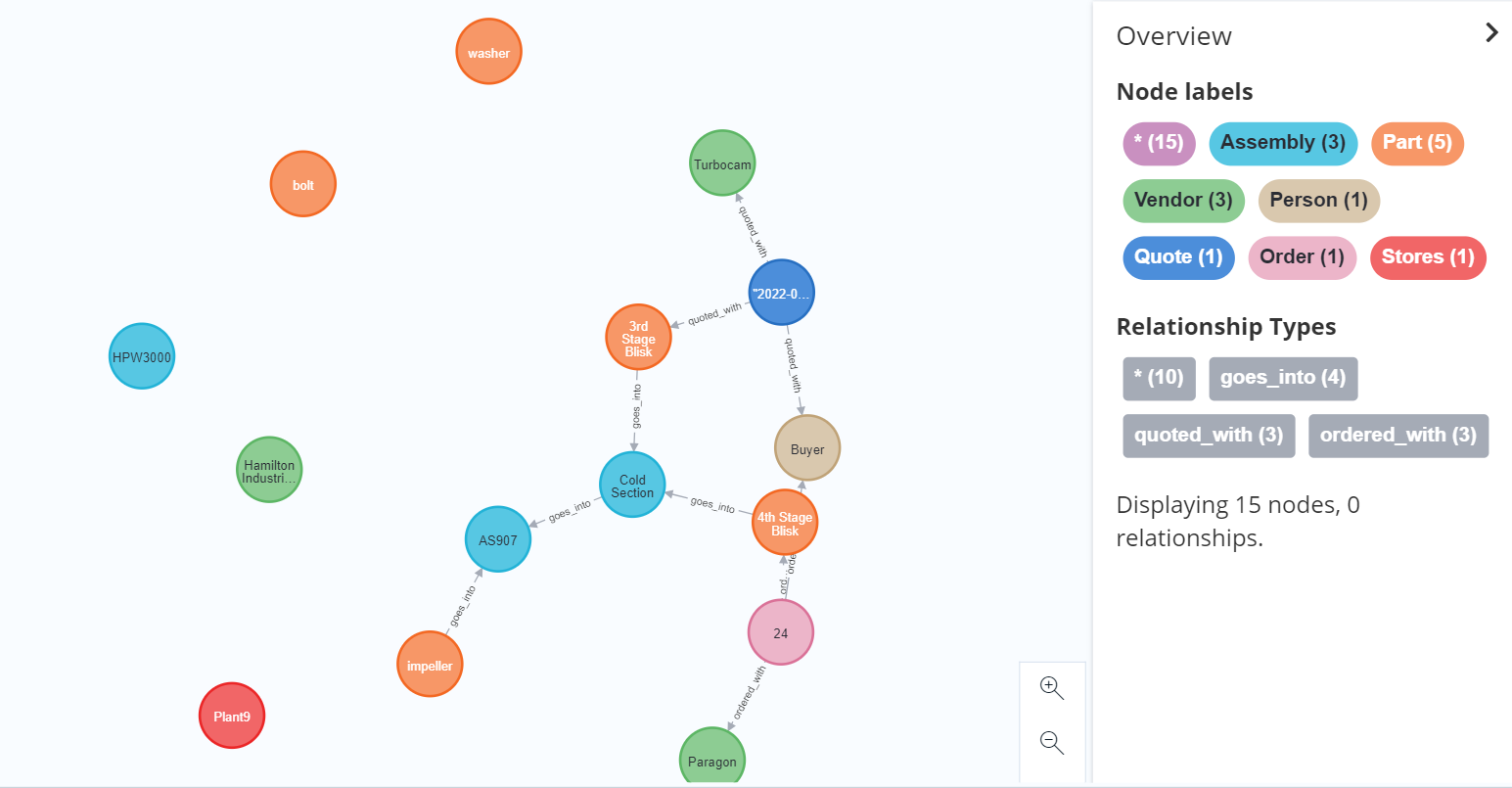
The first problem with the relational database is the inflexibility of the tables. The database manages multiple BOM’s for different parts of the program, keeps track of what parts in the BOM have had drawings made, and records all quotes and PO’s on the manufacture of parts. Doing this takes more than 6 separate tables. With this many tables, only simple changes to the schema can be made without getting into more complicated database migrations. Property-graph databases allow new properties to be assigned at nodes and edges at will and so would seem to be much more flexible then the relational database.
The second problem is the complexity of sql join statements 2. The sql queries I needed to make to pull the data from multiple tables get very long and unreadable. I have not gotten far enough in my experimenting with the graph databases, but it seems like the queries in graph query languages have the potential to be much simpler and more readable.
I’ve just started playing with the graph database there’s a lot to figure out. What is the correct schema for the database, and what exactly is a schema in a graph-database. What is the performance of a graph database relative to the relational3? How much coding will it take to create the interface to the database? Lot’s of questions to explore, but graph-databases definitely are interesting and seem to be a natural way to organize data in some cases.